
Replica: Informing Urban Planning with Synthetic Simulations

Replica aims to use machine learning and synthetic simulations to make urban planning more efficient and inclusive. Translating "real" data into "synthetic" data offers promise for addressing the privacy concerns critics have.
Replica, an urban planning tool spin-off from Google’s Sidewalk Labs, is leveraging data analytics to understand “how, when, where, and why people move around a region.” Having recently closed Series A funding of $11 million, Replica is working with cities Portland, Kansas City, Chicago, and Sacramento and is moving towards expansion.
How does it work?
Replica is built into two parts: its database and its data analysis tool (called Explorer). The database consists of all trips and activities of people in a region; the data is gathered anonymously via cell phone location data and demographics are recreated into a statistically representative “synthetic” population. Location data is translated into a “travel behavior model” which is then attached to a (synthetic) person. The data analysis tool Explorer is then used to simulate and generate a week of one person’s trips and activities (and is updated every 3 months to stay current). The Explorer tool then further allows users to generate maps, charts, simulations with various filters and data queries to understand how the population of a given area moves over time.
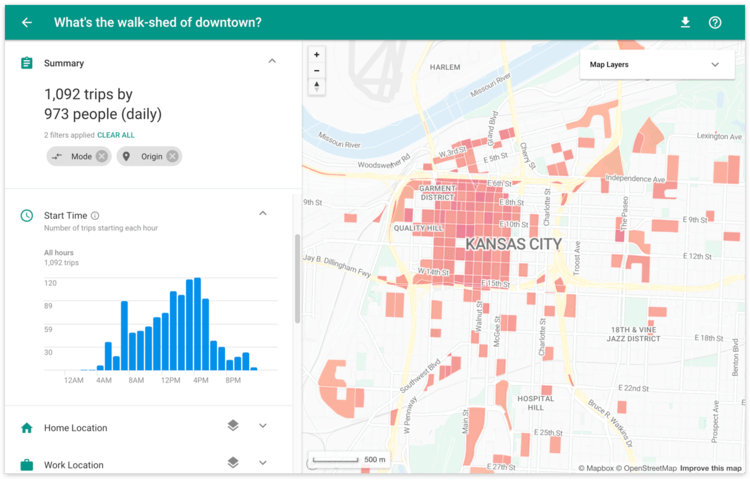
Generating Synthetic Data

Replica was born out of a need for better, more inclusive urban planning and development. Urban planners rely on people’s travel data to understand the link between transportation and land use; without relevant data, planners won’t be able to make good decisions on how land in used in a city and what forms of (often public) transportation is needed. This results in inefficient bus routes, overused sidewalks, inadequate bike lanes, or transportation options in low-use areas, among others.
Replica instead offers population data that is more representative, current and relevant. This allows city planners to add or subtract bus routes, bike lanes, and sidewalks where they are actually needed. The most important use of AI here is in the machine learning algorithms that takes inputs from cell phone data and census data to create a “synthetic” population. Why the need for this? Because cities are often restricted by privacy concerns from capturing more precise data on its population. By using an algorithm to generate a representative population, no one individual’s data is traceable thus addressing privacy concerns. This allows planners to have access to much more nuanced data, since it is representative and not actual, data they were not allowed to access before. [It’s worth noting that city planners did have ways of stripping personal identifiers from population data before, but the process was often time intensive and expensive. Here “synthetic” data offers a huge value add.]
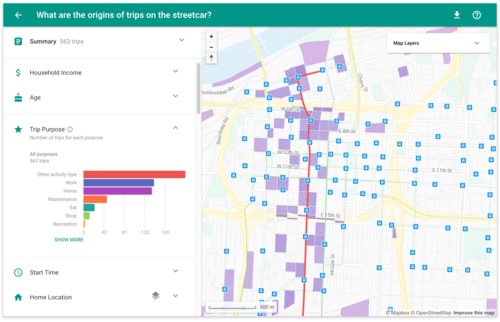
Building Travel Behavior Models
The other value creation component is in the travel behavior models built for each “synthetic” person in the population. Individual cell phone location data is used to train machine learning algorithms to generate representative travel behavior models (think of it as “mock” cell phone location data for the “synthetic” person). This again addresses privacy concerns while allowing planners to gather data at the individual (albeit disguised) level. These individual travel models outputted by the ML algorithm are necessary to then build the city-wide map of a population travel model. In the end, planners end up with a detailed map of how the population of an area moves about.
Running Travel Simulations
Finally, the greatest benefit Replica offers is the ability to run detailed simulations and generate findings in a matter of minutes. Typically, planning work can take months if not years; to understand if a new bike lane is effective, the bike lane must be installed, used, and analyzed over a period of time. But Replica offers the opportunity to run a simulation of the addition of a bike lane and understand its impact on not just the whole population but various groups. The ability to filter data and model specific queries allows a level of nimbleness that city planners have never known before. Being able to “play around” with ideas and alternatives online will inevitably lead to a better use of city funds and more inclusive city development.
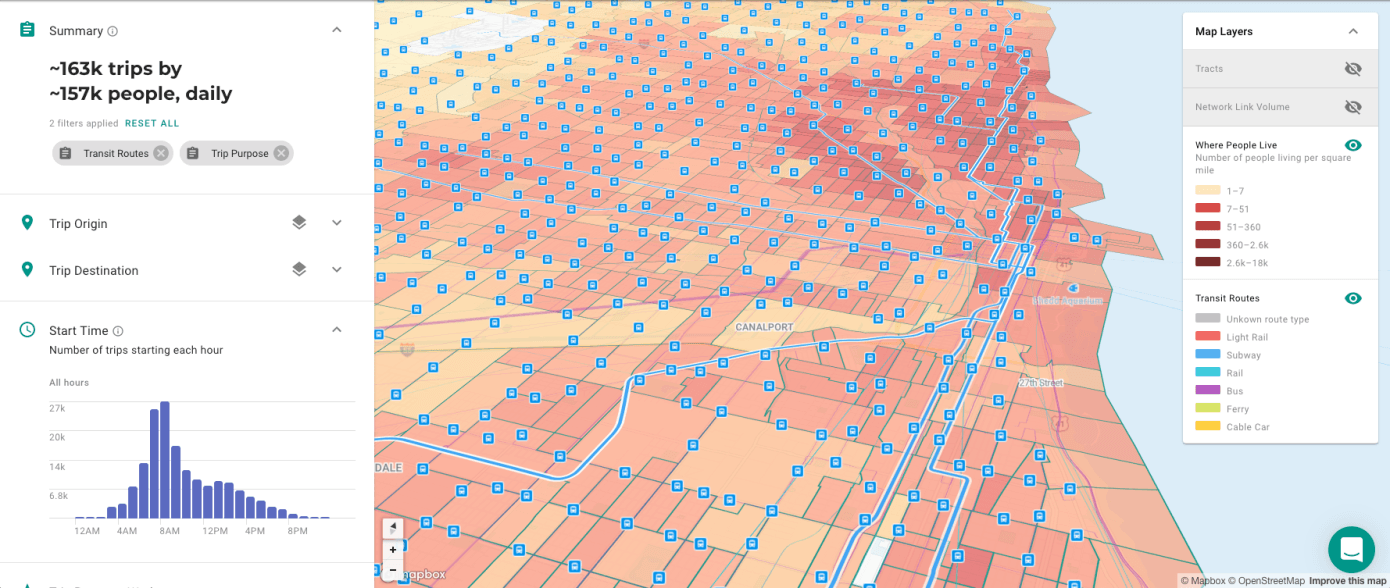
Despite everything Replica has done to address privacy concerns, agencies are still hesitant to adopt the new technology. Critics claim that despite the efforts to strip personal data, re-identification of individuals is still possible. Cities are also asking for more detailed information about the provenance of “synthetic” data and more clarity on what seems to be the “black box” of algorithms. Still, Replica offers a lot of promise for the future of urban planning and development.
- https://replicahq.com/#replica-section
- https://www.sidewalklabs.com/blog/announcing-replicas-spin-out-and-series-a/
- https://techcrunch.com/2019/09/12/sidewalk-labs-spins-out-urban-data-gathering-tool-replica-into-a-company/
- https://medium.com/sidewalk-talk/introducing-replica-a-next-generation-urban-planning-tool-1b7425222e9e
- https://govtech.com/biz/Replica-Raises-11M-and-Spins-Out-of-Sidewalk-Labs.html
- https://www.engadget.com/2019-09-12-sidewalk-labs-replica-series-a-funding.html
Interesting article! I am also a bit concerned about re-identification of individuals, since I would think that if you know just a few pieces of information about a person (home address, where they work, etc.) then it would be pretty easy to pick that person out of the data set. Still, it’s great that Replica is working with cities to get them critical behavioral data for their planning efforts, run simulations and facilitate impact measurement for completed projects.
This is a great article, thanks for sharing. When it comes to urban planning, it is a struggle to choose designs that may be more capital intensive yet result in happier people. Until happiness can be measured, I fear people will always choose the cheaper alternatives rather than those maximizing the comfort of civilians.