
I’m not a Robot!
How ReCaptcha helped Google digitize all books
If you spend any time on the internet, you’ve probably run into a box like the one below asking to confirm that you are not a robot.
How does it know you are a human? One clue is in the name on the right side of the box. CAPTCHA stands for Completely Automated Public Turing Test To Tell Computers and Humans Apart. The acronym was coined in the year 2000 by Luis von Ahn, Manuel Blum, Nicholas Hopper and John Langford in a paper they published at Carnegie Mellon University. While the test you see above mostly involves tracking the pattern and speed with which your cursor approaches and then clicks the box, the original CAPTCHAs required more work.
Back in the day
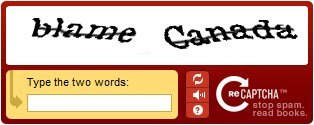
Shortly after the CAPTCHA paper was published, the first CAPTCHA tests appeared as security measures to prevent spam or fraud. For instance, CAPTCHAs prevented sophisticated scalpers from buying out a stadium on Ticketmaster by writing algorithms to automatically buy two tickets at a time. The early versions had users confirm their humanity by reading distorted strings of text contained within an image – a task easy for humans and hard for machines.

Harnessing human brainpower
A few years after introducing CAPTCHAs, its inventors realized that over 200 million CAPTCHAs were being typed up every day. They decided to make better use of the 10 seconds most people were willing to give in order to prove they had 23 chromosome pairs, while still harnessing humans’ special ability to decode hard-to-read words. The Carnegie Mellon researchers founded a startup called reCAPTCHA that set out to digitize the world’s books.

Many sophisticated optical character recognition (OCR) algorithms were already on the market and fast at work to digitize printed text. However, even the best OCR struggled particularly with words in books printed over 50 years ago where the ink was faded, distorted, or stained. For the 30% of words that OCR could not recognize, reCAPTCHAs filled the gap by making humans read them before checking out or before signing up for a newsletter.

The first word is known and used to verify security. The second word is from a printed book that is being digitized for the first time.
Once sites like Facebook and Twitter adopted the reCAPTCHA solution, the company quickly surpassed digitizing 100 million words each day (or 2.5 million books per year). In 2009, Google acquired reCAPTCHA and directed its power to Google Books and Google News Archive. Together, they achieved the goal of digitizing books by getting 750 million unique users worldwide to read one word at a time, for free.
Proof it’s replicable: then came Duolingo
Luis von Ahn’s achievement got him to wonder what else could he achieve through free crowdsourcing. Noting that translation is another task at which humans are still better than software, in 2011 von Ahn launched Duolingo – a platform to learn a new language while simultaneously translating the web. Much like reCAPTCHA, Duolingo combined the unique human skill with the user’s high motivation to complete the task. In translating web content, users are learning a new language for free, while the leading alternative (Rosetta Stone) costs users hundreds of dollars. Users are also more engaged that with alternative solutions, given that they are reading and translating real and current content. The platform surpassed 100 million users in 2015. Google Capital invested $45 million in Duolingo that same year. Is a Google acquisition over the horizon?
Sources
[1] https://www.youtube.com/watch?v=-Ht4qiDRZE8
[2] https://www.cs.cmu.edu/~mblum/research/pdf/captcha.pdf
[3] https://googleblog.blogspot.com/2009/09/teaching-computers-to-read-google.html
[4] https://www.keithrozario.com/2011/12/recaptcha-4-requirements-crowdsourcing.html
[5] http://www.pcmag.com/article2/0,2817,2402570,00.asp
[6] http://venturebeat.com/2015/06/10/100m-users-strong-duolingo-raises-45m-led-by-google-at-a-470m-valuation-to-grow-language-learning-platform/
Great post Andrea! I had no idea that I was helping to digitize books every time I types those words, and I would assume that most consumers were also not aware. This is an interesting example of crowdsourcing with a crowd that does not really know that they are involved in the project. This probably helped with the accuracy of the digitization because people thought they needed to type both words correctly in order to move on. Also, the crowd does not really have a choice to opt out, since they need to type the words in order to reach the next webpage. This probably makes crowd management much easier.
Hi Andrea,
Really cool post! I didn’t know I was being crowdsourced for this! It’s a great idea because the crowd is actually forced to do this little favor for the platform.
I wonder if they will run out of old books some day? Unless they find an alternative volume of valuable, machine-unreadable texts, the value behind this method will run out as well.