
Slack’s Battle Against Information Overload

Slack was supposed to make businesses more productive but instead made information overload worse. Could it use machine learning to fix this information overload problem?
Slack, a business to business collaboration application was born out of a growing frustration with email. Employees in organizations big and small were spending almost a quarter of their work day [1] on email, and yet felt out of the loop on what was going in the organization.
Slack’s value proposition was to be the modern email: to allow users to communicate with each other in a more quick and concise fashion while allowing for better transparency and relevance. And Slack took off, becoming the fastest growing enterprise application in history [2]. But as Slack made workplace conversations easier, quicker and more transparent, there was a lot more information available, and instead of being overwhelmed by 50 emails employees were now overwhelmed with 100 slack messages instead. What was supposed to fix email fatigue had made the information overload problem worse. But that’s where machine learning comes in. By making machine learning an integral part of product development, Slack can filter the signal from the noise for its users and live up to its promise of being a more productive way to communicate.
Fortunately, Slack is aware of and has started to tackle information overload as their CEO acknowledged: “The flip side is there’s a lot more information. We’ve already put in hundreds of little things that collectively reduce the impact of massive flows of information in Slack.” [3]
Some of these little changes they have made in the short term are to put in better user controls such as to control notifications based on channels, to mute channels or people, and a do not disturb mode to turn off notifications automatically based on time of day.
In 2016, Slack also recognized the importance of Machine Learning in solving this problem and made a key organizational change with an eye towards the longer term. They established a Search, Learning and Intelligence group (SLI), with the charter of making users more productive, informed and collaborative. [4] Progress from the team has been slow so far. Their major product launch called Highlights, which was supposed to show users their important unread messages, has not been received well on social media, with most users finding the suggestions irrelevant. [5]

I believe that while Slack has identified the right problems, management hasn’t taken the right steps to fix it and I would do three things differently.
In order to understand what content is relevant to someone, Slack needs to understand who a given person cares about in their organization. So the first thing I would do is to first focus on using machine learning to develop a robust “Organization Graph” akin to Facebook’s “Social Graph” [6] which maps the strength of the relationship between a given person and each of their Facebook friends and powers their ranking algorithms [7]. Getting this right will serve as a foundation upon which many product features can be built such as an improved search functionality and an improved Highlights.
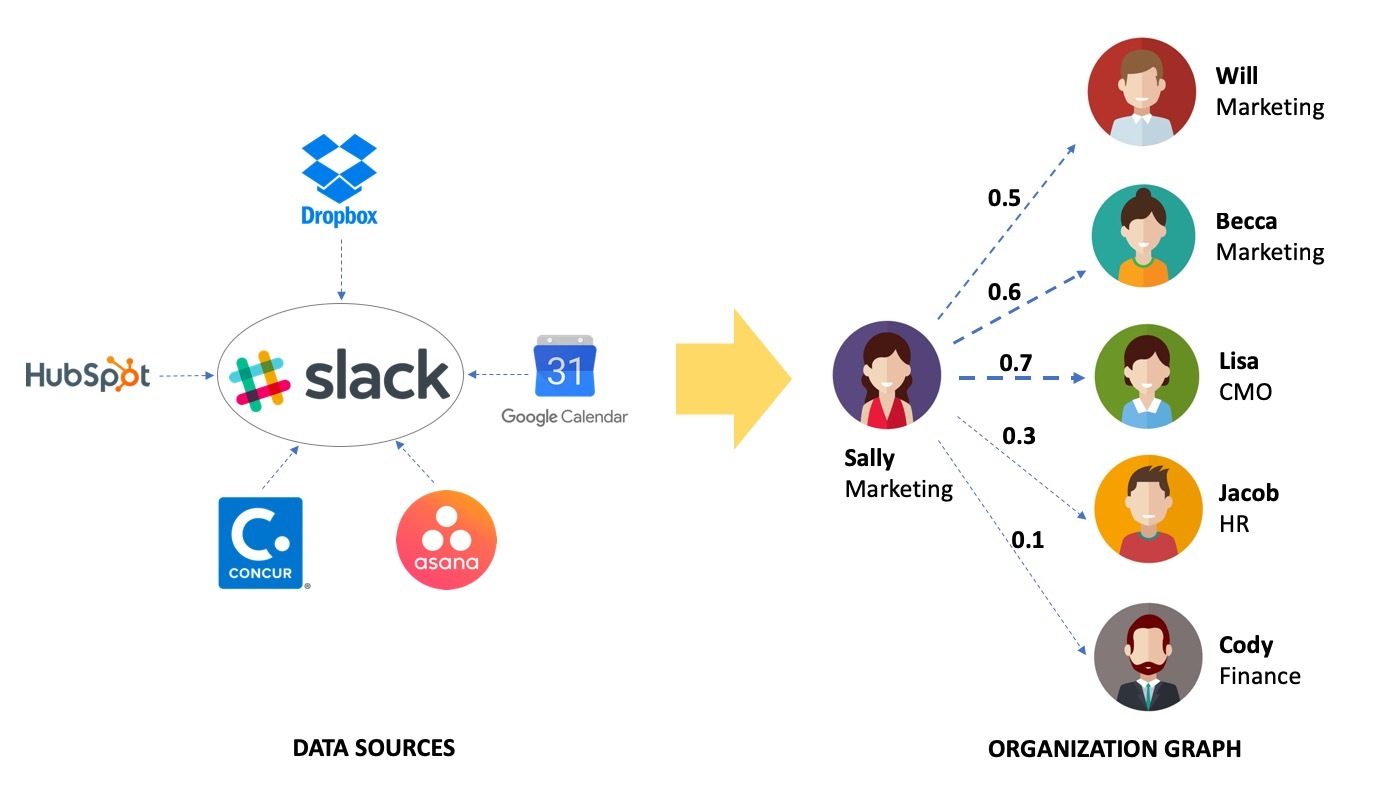
Second, I would begin to use third party data from apps connected to Slack (e.g., Google Calendar and Dropbox) through its growing platform in the machine learning algorithms. This data on activity like which users often share files or have meetings or work on tasks with each other can be extremely useful in determining the aforementioned Organization Graph and identifying what messages are important to users at a given moment of time.
Slack can use Machine Learning to create an Organization Graph which it can leverage to identify high-signal content personalized for each userLastly, from an organizational perspective, the SLI team located in New York is the only one currently leveraging machine learning at Slack which is not enough in the long-term. It is also located away from the other product teams which are in San Francisco and actually own the product surfaces that make up Slack (e.g. the Channels or Direct Messaging surface). To remedy this, I would narrow the scope of the SLI team to focus on the broad machine learning algorithms and foundational infrastructure such as building out the Organization Graph which can then be used by the other product teams and encourage and equip other product teams to build on top of this infrastructure using machine learning to improve the product surface they own.
One thing I struggle with is how to balance “fixing” information overload with allowing for transparency and a feeling of being informed. After all, one of the upsides of Slack is that it makes much more information within an organization accessible to everyone. In an ideal world, Slack could present a list of the 10 messages you really need to see, filtering away the 100s which were noise. But perhaps amongst that noise there was some serendipity lost as well?
(796 words)
Sources
[1] McKinsey Global Institute. 2012. “The Social Economy: Unlocking Value And Productivity Through Social Technologies”. https://www.mckinsey.com/industries/high-tech/our-insights/the-social-economy.
[2] Bessemer Venture Partners. 2017. “State Of The Cloud 2017”. https://www.slideshare.net/ByronDeeter/state-of-the-cloud-2017-72021644.
[3] Woyke, Elizabeth. 2018. “Stewart Butterfield Talks About How Machine Learning Can Help Your Work Productivity”. MIT Technology Review. https://www.technologyreview.com/s/608953/slack-ceo-how-well-use-ai-to-reduce-information-overload/.
[4] Weiss, Noah. 2018. “Starting Up Slack’S Search, Learning, & Intelligence Group In The New NYC Office”. Medium. https://medium.com/@noah_weiss/starting-up-slack-s-search-learning-intelligence-group-in-the-new-nyc-office-af6523090789.
[5] “Slackhq’s Tweet”. 2018. Twitter.Com. https://twitter.com/slackhq/status/903323086862376962?lang=en.
[6] Ugander, Johan, Brian Karrer, Lars Backstrom, and Cameron Marlow. 2018. “The Anatomy Of The Facebook Social Graph”. Arxiv.Org. https://arxiv.org/abs/1111.4503.
[7] Zuckerberg, Mark, and Andrew Bosworth. 2006. Communicating a newsfeed of media content based on a member’s interactions in a social network environment. US8171128B2, and issued 2006.
Amazing read. As a recent adopter of slack (by force) I found great parallels between what ML is trying to do in this space, and things like Yahoo news digest. There are three risks that I see apparent in this approach. Firstly, users must be actively aware that messages that they open will be used as predictive tools regardless of their utility to the user. The convergence of preference will only be apparent after many an iteration, which could compete against user utility in the short term. Another area of concern is pigeon-holing, where the program might limit visibility to things that users have not historically expressed interest in, even though they might be interesting to the user. This alludes to assumptions regarding dynamic preferences. I suffered this problem after changing industries in work and having my dynamic platform take well over a month to transition in response. Would love to hear your thoughts on these two matters!
This is a very interesting paradox. Slack was built to foster communication across the organization. However, more communication can increase the “noise” within an organization and ironically decrease the flow of important information to the people who need it. The risk with adding machine learning to the mix is that information the machine does not deem important could be filtered out and overlooked. While you can make the case that this will happen once and then the machine will learn not to make that mistake again, there is the risk that the information is critical and if overlooked could cause serious harm to the company. Overall, machine learning looks promising in this regard, but it doesn’t come without risks.
Great article! There have been a lot of recent developments to text summarization in machine learning and NLP algorithms, specifically in extraction and abstraction based summarization. Perhaps Slack could use this instead of highlights to summarize the missed messages per channel between when a user has last interacted with slack. Agree with the comment above that if people solely rely to get their information, then could be dangerous if this algorithm doesn’t work 100% of the time. One thing to accommodate that case is to include a slack specific tag, perhaps the *bold* tag so that any text delivered in bold is deemed extremely important and automatically included in all summarizations.
Great read! As a recent Slack user, I can certainly resonate with this pain of managing information both within the app and across apps. In response to the risks of missing information in the comments above, perhaps ML can be used to prioritize the messages based on a rank of importance, rather than filtering out messages.
This was a great read. Your recommendations indeed seem to better inform Slack on what it should prioritize for its users. In particular, your suggestion of seeing how users interact on other platforms such as Dropbox and applying that information to prioritizing messages was compelling. I can see how interacting heavily with one user (exchanging files, etc) would make it so that I want to hear from that user. I would even consider letting your users/org be super intentional about how to limit the flood of info, and give them a feature where people can limit themselves to only 10 messages a day. If they do that, perhaps people will be much more mindful about what they share. Perhaps different channels can have different parameters — like #companyannouncements will only have 2~3 admins who can post twice a day on it, while #randomblabberings will be a steady stream of free flowing online chat like convos. Overall, if Slack truly wants orgs to fight info overload, then they should limit the traffic in the first place, whether through strict time limits (30 minutes a day) or message frequence limits (10 messages a day).