
Minimizing Decision Fatigue Through Machine Learning @ TripAdvisor

Despite the many convenience benefits of the internet, information overload is real. And with that comes decision fatigue. Machine learning is helping review platforms, like TripAdvisor, cut through all the fluff to get you to a decision faster.
![]()
Every day, we make approximately 35,000 decisions. [1] It is undeniable that technology has played, and continues to play, a huge role in making our lives more convenient. However, information overload and the sheer abundance of choice that the internet offers only adds to the decision fatigue epidemic. Research has shown that our cognitive resources are scarce and we tend to feel depleted by decision-making. [2] Machine learning (ML) is helping to limit the effects of information overload on crowdsourced review platforms, making them better decision-making aids. The machine learning megatrend is moving review platforms towards becoming recommendation platforms, as users want technology to be more decisive. One such review platform is TripAdvisor, which has become an instrumental tool for travelers looking to make decisions about what to do on their trips.
At present, TripAdvisor is working on hyper-personalized rankings and optimizing the helpfulness of reviews. By limiting the amount of information that users have to decipher to make a decision, TripAdvisor is moving closer to becoming a recommendation platform.
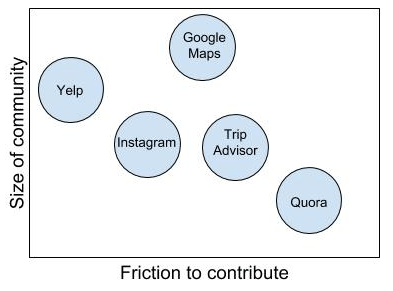
To help frame how ML is shaping TripAdvisor’s product direction, it is important to understand the current limitations for recommendation platforms. As per diagram 1:
- Reliance on a large community that the user can lean on for advice
- Friction for users to contribute their opinions.
Machine learning can solve for these, as it can reduce platforms’ reliance on a large user base that is incentivized to contribute reviews. All they would need is a critical mass of user contributions as “training data”. However, full reliance on AI with no additional user contributions would require a steady state for users’ preferences. That’s when the model’s learning patterns are not future-proof and the “over-fitting” phenomenon comes into play. [6]
Personalized Ranking

Besides the current ranking algorithms, there is a slew of launches around personalized recommendations in different parts of the product. For example, TripAdvisor’s email digests include a collection of algorithmically-curated suggestions.
Review Helpfulness
TripAdvisor has too many reviews for human moderators to rank which ones to display. In response to this, they built a classifier for scoring whether a review’s text is likely to be helpful to other travelers or not. However, the current performance is only sufficient for filtering reviews to route to moderators, but “even at its best precision, it has too many false positives to auto-reject any reviews.” The classifier still isn’t capable of operating without human intervention. [5]
Longer term, there are indications that TripAdvisor is working on more predictive tools. For example, for review helpfulness, “taking into account the user’s review writing history; if they’ve written helpful reviews in the past, perhaps we’ll give them more benefit of the doubt on a marginal review.” [5]. TripAdvisor is feeling the pressure to become more directive. Hence, the real power of the mega-trend will be realized with TripAdvisor’s broader vision to be able to take into account user preferences, as well as various user-generated reviews, to provide users with one definitive suggestion that would best suit them and the occasion.
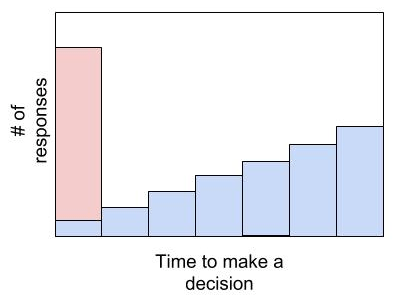
Training the classifier to serve one recommendation based on a weighted average of user-generated reviews (for example, weighted by the credibility of the reviewer) has major limitations.
Reflecting on how we seek recommendations in reality, we engage with one person at a time and seek their advice. With each 1:1 interaction, we can get an extra ‘datapoint’ that helps us make a reasoned decision. We also sometimes poll a large group of people to gauge the majority view on a topic. Despite taking longer, I would hypothesize that a string of 1:1 interactions are more effective at taking into account context. This dichotomy is visualized in diagram 2.
In the context of ML on TripAdvisor, the latter case holds and it is a major concern that only a limited amount of information is included in predictive models. The issue of TripAdvisor tapping into the hivemind and averaging responses to compute a recommendation in real-time is an important consideration for their product team.
In general, it is important to keep in mind that personalized recommendations are “forecasts of people’s preferences, and they are helpful even if they won’t tell you why people like the things they do, or how to change what they like.” [6] This raises the question of what users’ expectations of a machine-generated recommendation are?
Additionally, there is the issue of the standardization of decision-making. The call for a specific decision – which restaurant should I go to, for instance – would be met by the standardized result of social understanding, therefore flattening individual choice into social conformity, which raises the question of whether minimizing decision fatigue through machine learning is at the expense of individual agency?
(Word Count: 782)
[1] Sahakian, B. J.; Labuzetta, J. N. (2013). Bad moves: how decision making goes wrong, and the ethics of smart drugs. London: Oxford University Press.
[2] Rudiger et al. (2013). Effort reduction after self-control depletion: The role of cognitive resources in use of simple heuristics. Journal of Cognitive Psychology.
[3] Polman, E., & Vohs, K. D. (2016). Decision Fatigue, Choosing for Others, and Self-Construal. Social Psychological and Personality Science, 7(5), 471–478.
[4] Amis, G. (2015) Which of TripAdvisor’s reviews are actually helpful? Engineering & Product Operations TripAdvisor Blog. http://engineering.tripadvisor.com/which-of-tripadvisors-reviews-are-actually-helpful/
[5] Yeomans, M. (2015). What every manager should know about machine learning. Harvard Business Review.
[6] Lake. Stitch Fix’s CEO on selling personal style to the mass market. Harvard Business Review 96, no. 3 (May/June 2018): 35-40.
I tend to face decision fatigue all the time with the influx of new applications that are supposed to facilitate better decisions but often result in analysis paralysis or option overload. I’ve even come to appreciate restaurants that have an extremely simple menu with less than 20 items which reduces the amount of choices I need to make everyday. I think it’s great that TripAdvisor is looking to leverage AI and ML to better serve personalized recommendations based on my app usage history.
To answer your question, I do agree that by using predictive analytics to help make decisions for humans, we will lose a certain aspect of individual agency. However, does it really matter? There are definitely some decisions which I want to know all the options, pros and cons, and want to spend a lot of time pondering (i.e. moving to a new location, career change, etc.). However, with certain decisions like deciding where to eat on a travel application, or which park to visit, these decisions have little bearing on my long-term happiness, and I would imagine it is similar for most people. Thus, I fully support the use of AI and ML for better help in making more trivial decisions like this everyday.
As a consumer, I can attest that decision fatigue is very real. With abundance of goods and services in any given category, even the most basic task such as shopping for let’s say sour cream becomes exhausting, not to mention vacation planning which is rather expensive and significant for majority of people. Any technological advancement that would help to optimize that decision process would be a huge hit. However, it’s important to note that decision fatigue is driven for high extent by fear of making a sub-optimal decision that will result in attaining lower value. Recommendation engines were among the first real-world applications of machine learning, dating back to when Amazon was shaping its first online bookstore platform. The question is – how comfortable is the customer with actually trusting synthesized recommendations? Would there be a concern that recommendation engine results are skewed, either intentionally to promote a certain product, or unintentionally due to inefficiencies in training data. I think that Tripadvisor should look for ways to organically embed the results of machine learning algorithm outputs into different aspects of user experience.
Great writeup! I love the Idea of trying to reduce the seemingly never-ending amount of decisions that one must face everyday. I do wonder, however, if vacationing/travelling is truly the place to try though. Does reducing the decisions of a person who is using TripAdviser help or hurt their business. I travel a lot and I know that when I use TripAdvisor, yes I am looking for something to do in an area of the world that I’ve never been before, but I am also looking for something new that I wouldn’t have thought of before. My concern is that for the person who has never before expressed interest in diving or surfing, would the algorithm still suggest that person go diving when he/she is in Cairnes or would it suggest surfing when in Bali?
I think that this technology and this particular idea does have merit, however, predicting the future tastes of a person (especially one who is in an unfamiliar location) may lock them into decisions that reflect their past actions and not actions that may be novel and worth trying.