
Dial-an-Algorithm: Using Machine Learning for Child Welfare Screenings

Should algorithms intervene when child welfare is at stake?
Every day, hotline screeners for child welfare agencies across the United States hear allegations of child abuse that range from suspicious to shocking. For each call, screeners need to decide, often within less than an hour, whether a caseworker should intervene and physically investigate. An error in their judgment – which requires weighing a tangled history of cross-functional data, including from child protective services, mental health services, drug and alcohol services, and homeless services – puts lives directly at risk [1].
Allegheny County, PA: The Allegheny Family Screening Tool (AFST)
Allegheny County has deployed machine learning to generate a predictive “risk score” for the child in question. Previously, it was nearly impossible for a case worker to search all data streams involving the child, their relatives, the potential perpetrator, or other adults who may be related to a referral, within the time required to make a screening decision [1]. The “width” of the data to be plumbed within such a narrow period made it a promising process for predictive modeling. Weighting that data had been left to the screener’s discretion, leading to inconsistencies in rationales and evaluations of which factors were most predictive. As a pediatrician at the Children’s Hospital of Pittsburgh explained, “all of these children are living in chaos… how does [the agency] pick out which ones are most in danger when they all have risk factors?” [1].
In 2014, Allegheny County released a Request for Proposal (RFP), funded under a public-private partnership, to address the issue of ineffective intake screenings. The County had determined that 4 in 5 fatalities occurred for children who were reported to a hotline but not passed along for a subsequent intervention [2]. The selected team from the Auckland University of Technology developed an open-source model that was further reviewed under secondary RFPs issued for an ethical evaluation and an impact evaluation [3].
The Allegheny Family Screening Tool (AFST), which launched in August 2016, assigns a score between 1 and 20, from lowest to highest risk, to each reported case of abuse or neglect. The predictive model is based on 76,964 referral records in Allegheny County between April 2010 and July 2013, which contained more than 800 associated variables [3]. The tool aims to screen out children who are at low-risk of being re-referred, reducing investigation expenses and the emotional disturbance to families, while screening in children who are at high-risk of being placed in foster care and more likely to need intervention [4].

While cases that receive a score higher than 16 automatically trigger an investigation, the score is otherwise supplemental for the screener to consider [2]. Allegheny County has seen substantial improvements in flagging high-risk cases and avoiding low-risk ones using the predictive model, and found that without the tool, 27% of highest risk cases were screened out and 48% of lowest risk cases were screened in [2].
Algorithm Implications and Next Steps
While early results are promising, algorithms that dictate social services delivery remain controversial because the underlying data can be subject to racial or ethnic biases. However, the ethical review of Allegheny County’s screening tool concluded that the tool mitigates more than extends human bias from entering the process, stating “it is hard to conceive of an ethical argument against use of the most accurate predictive instrument” [1]. My recommendation to Allegheny County would be to continue refining the model and to maintain an independent ethical review body that assesses program implementation annually. The county should further consider building upon the trove of internal lessons learned to identify complementary programs where predictive modeling could optimize local resident outcomes and administrative expenses.
One question I have involves the appropriate use of private contractors in developing these algorithmic models. In practicality, public agencies rarely have funding or internal capacity to produce these tools in-house, leading them to rely on companies who may refuse to share their predictive analytics given intellectual property (IP) risks. Mindshare Technology is a company that has produced Rapid Safety Feedback, a package adopted by child welfare agencies in at least five states [1]. The company has declined to disclose the workings of their tool, despite recent fatalities of children who were not marked by their algorithms as “high risk.” Allegheny’s tool is publicly owned, and the team has released details for further academic scrutiny and public hearings, but that approach may be an exception rather than the norm. As governments turn to private partners for help incorporating AI or machine learning, how should companies navigate public expectations about transparency, particularly in areas prone to biased data, while protecting the intellectual property that gives them a competitive advantage in this market?
Word Count: 770
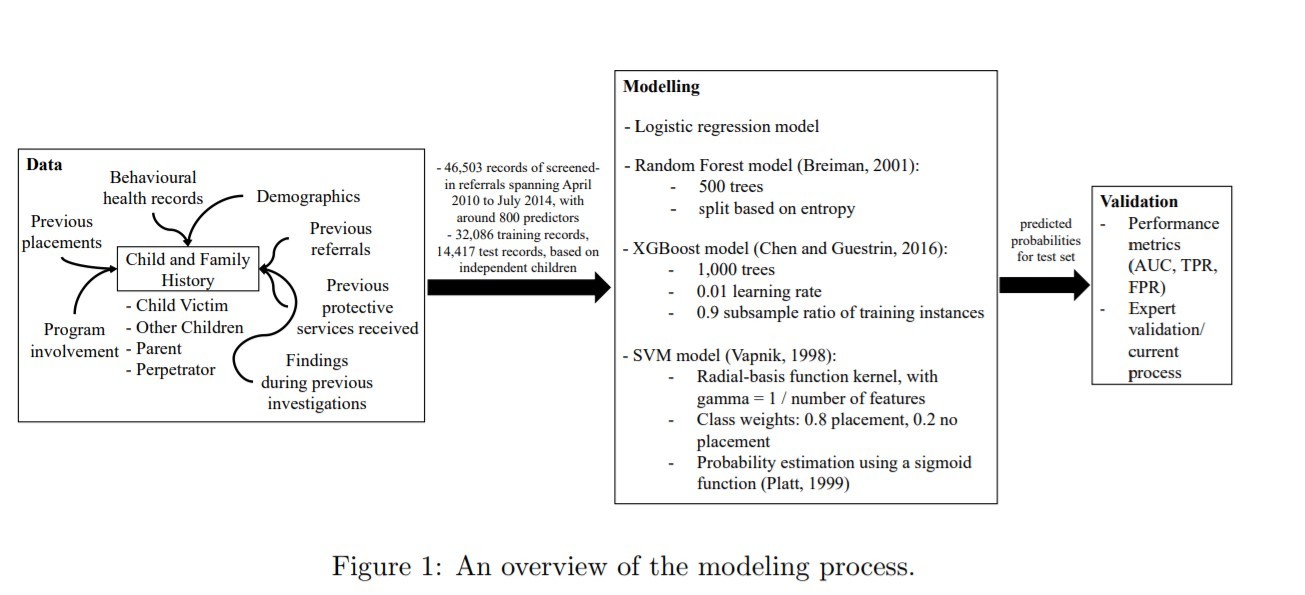
Modeling Process for AFST [4]
Sources
[1] D. Hurley. Can an Algorithm Tell When Kids Are in Danger? New York Times (January 2018). https://www.nytimes.com/2018/01/02/magazine/can-an-algorithm-tell-when-kids-are-in-danger.html.
[2] E. Dalton. Using Predictive Modeling to Improve Child Welfare Decision Making in Allegheny County, PA. Optimizing Government Workshop Presentation, delivered by Dennis Culhane (April 2017). https://pennlaw.hosted.panopto.com/Panopto/Pages/Viewer.aspx?id=fea481ac-788b-4686-9302-34d23c40d3ba.
[3] Developing Predictive Risk Models to Support Child Maltreatment Hotline Screening Decisions. Centre for Social Data Analytics (March 2017). https://www.alleghenycountyanalytics.us/wp-content/uploads/2017/04/Developing-Predictive-Risk-Models-package-with-cover-1-to-post-1.pdf.
[4] A. Chouldechova, E. Putnam-Hornstein, D. Benavides-Prado, O. Fialko, and R. Vaithianathan. A case study of algorithm-assisted decision making in child maltreatment hotline screening decisions.
This is an excellent take on how machine learning can be used to improve performance in jobs that have traditionally been performed by humans. In particular, I find it very impressive that machine learning can be used to address a very sensitive and important social situation that has long evaded being solved by policy.
However, a 27% false negative rate seems exceedingly high. Since the false positive rate is not as important, I am curious to know if there is a possibility of reducing the number of high-risk cases that are ignored by the system, while potentially increasing the number of low-risk cases that are flagged, as the latter does not seem to pose a critical problem.
I love the discussion on the ethical considerations of the racial and ethnic biases, but respectfully disagree with the quote from Marc Cherna’s report (paragraph 1 under ‘Algorithm Implications and Next Steps’). If the system is selectively rejecting high-risk cases of a certain ethnic group, I believe that it is very critical that this bias be acted upon, or that human operators intervene in such situations.
It is inspiring to hear that machine learning technology is being applied to a governmental agency. I think the public-private partnership is ideal because it helps bring innovation to a sector that is traditionally lacking in resources. I think companies should be transparent when discussing the ways in which the technology is applied even if they aren’t sharing the details of the technology’s inner workings. I am curious if this same framework could be applied to similar government agencies in cities across Pennsylvania and across the country. How easy is it to integrate machine learning into existing databases while protecting the integrity and privacy of the data?