
Yelp is Failing its Customers – Rating Systems and the Challenge of Discovery

Yelp ratings cluster almost entirely between 3.5-4.5 stars and tend to slow down the discovery process. This leaves the door open for more user-friendly alternatives and new curated services.
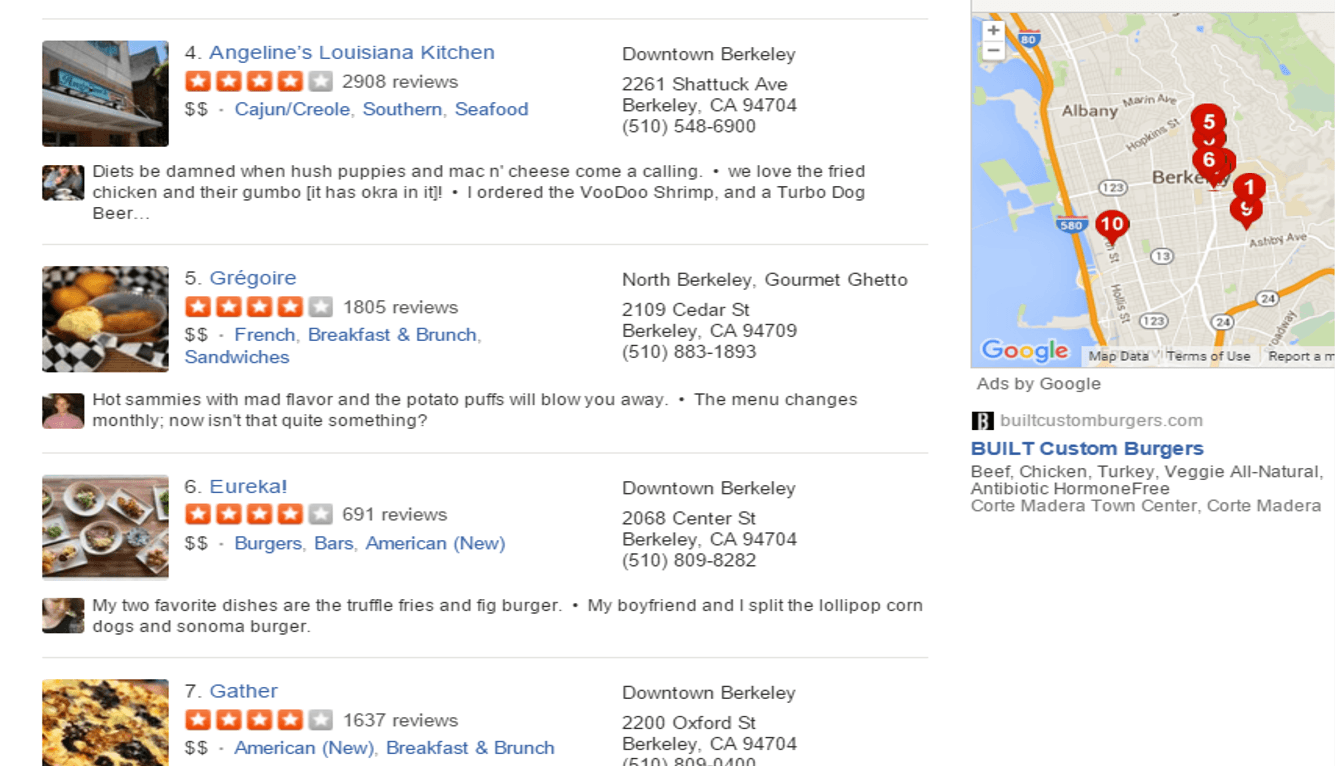
On a recent trip to Berkeley, I searched Yelp for “$$” restaurants and ran into a common problem – almost all of the top results seemed to have 4-star ratings (with hundreds or thousands of reviews). After 20 minutes of sifting through long-winded, often contradictory opinions, I felt frustrated and chose a place randomly.
Yelp and sites like Amazon are commonly used to discover the best choice among dozens of similar options. Over time, these review systems have accumulated hundreds of millions of crowdsourced data points and should theoretically enable better and more efficient decision making among users.
Then why does it seem like every decent place on Yelp has a 4 or 4.5 star rating? To test whether or not this was true, I scraped data from Yelp for the first 1000 hits for restaurants in Berkeley. For every restaurant, I recorded the price range, average rating, and number of reviews.
After throwing out restaurants with less than 20 reviews, 86.4% of all restaurants have between a 3.5 and 4.5 star rating. 74.4% of all restaurants have either a 3.5 or 4.0 star rating.



So, despite having such a rich data set, Yelp does not succeed at placing restaurants on a true 5 star spectrum of quality (equivalent to a 10-point scale since there are half stars). Rather, it tends to place them in 2 or 3 buckets of “decent”, “pretty good”, and “very good”.
Oftentimes, you’ll need to make a choice between 5 or 6 “very good” options and Yelp will leave you with written reviews to sort through. How does Yelp deal with this challenge? With hundreds of reviews available for popular locations, the order in which reviews are presented ends up being critical for how a restaurant is perceived. Not surprisingly, there have been many allegations against Yelp of selective ordering by business owners who decided not to pay up, and this has resulted in over 2000 complaints to the FTC through last year.
Discovery 2.0
Given the inefficiency of distinguishing between options on Yelp, it’s not surprising that a new generation of curated discovery sites has begun springing up. Product Hunt and Gogobot are up-and-coming examples. Other services such as the HBS startup Thrsday offered to take the headache out of planning an evening by curating the entire thing for you and a date.
Is hand-curated content the final form of discovery, though? I don’t believe so. Yelp has a treasure trove of data stacked up, but they just aren’t using it in a way that makes discovery, and ultimately comparison between similar options, as easy as possible.
Instead of an average star rating, which tends to unhelpfully cluster results, users should be able to quickly see how others with similar likes specifically ranked a subset of choices. Such a dataset could be generated by presenting reviewers with a series of binary choices between establishments within specific subcategories.
Well established algorithms could be used to produce stack rankings of establishments based upon a large number of binary choices by reviewers. Rather than being static, these rankings could be tailored to each specific user’s tastes based upon their selections of binary options as well. The end result could be a personalized rating similar to what Netflix uses based on a viewer’s preferences compared to the broader crowdsourced dataset.
Yelp’s competitive advantage is entirely based on its proprietary mountain of user-generated reviews, but as the sheer amount of data to sift through grows larger over time, Yelp’s user interface will become less and less useful in it’s current form. Users will also become less patient and demand the most relevant information to be presented quickly and efficiently. Since modifying the discovery process may damage Yelp’s existing business model, they are unlikely to make the changes necessary to fully optimize the user experience. This leaves the door wide open for new competitors who can somehow bridge the data gap.
I really like your suggestion of having Yelp provide recommendations based on your preferences, instead of overall average star ratings. To make this happen, Yelp would need to figure out a way to collect what your preferences are, first. Maybe if there was a check-in feature to prove that you went somewhere, or collection of GPS data so Yelp could understand where you have visited for 20+ minutes at a time so they could make the reasonable assumption that you ate at that location.
Atima,
GPS data is definitely a good start, but how about all of those 20+ minute restaurant visits that you hate and suffer through? What if Yelp sent a quick, low-friction notification to your phone that asked “did you like the food, yes or no?” Then, after getting the initial data point it could ask for a more complete review. Even without that review, though, Yelp would have a better idea of what types of places you like.
Really interesting insights! Very cool to see the data on review ranges. I have had a similar suspicion but never took the time to prove it.
Your suggestion on how to give people personalized recommendations is more or less what Foursquare has been trying to do. I think, in theory, it makes a ton of sense. I’m not sure whether it was the Swarm debacle, or something else that has kept Foursquare from growing with this approach, but it doesn’t seem to have caught on in a big way.
One thing I think would be really helpful would be a way to see ratings and sort reviews by who is local vs. a visitor, much like you can filter to elite Yelpers. It’s really hard to figure out, especially in tourist-heavy areas, whether you’re getting the best version of something in a city, or just the most well-known by tourists. I’d take a review into account much more heavily if it came from a local and/or someone who has reviewed a number of similar restaurants before.
Very interesting post Austin! I am surprised by the data analysis that you provided and it has opened my eyes to a problem with Yelp that I was unaware of. I think the real problem might be the way Yelp attracts customers to write reviews, as the data that we see is only from users who are actually interested to write a review about a restaurant. It would be interesting to see whether users of Yelp write a review when they are happy or disappointed. It could be the case that users only spend the time to write a review if they felt the food and the restaurant was worthwhile spending a few minutes to write something positive. I personally would only spend the time (which I never did) if the restaurant was outstanding or extremely disappointing. For example, I have written one review only on TripAdvisor when I was very unhappy with the experience because I felt that other people really need to know how bad the hotel was. Another problem is how subjective the review process is and how most people might feel in the middle about things in life in general, and it would be interesting to see whether that is actually the case. As for personalized recommendations, that would be truly valuable, but it would require users to state their preferences, which is time consuming and people might not want to invest time in the process if they have no proof that it would be valuable. I would personally prefer to ask people directly about their favorite restaurants in a city when I am traveling, or I would use Google search to look for options and take the time to read about the restaurant and check their menu. Generally speaking, I get a better feeling about a restaurant by looking at their menu and photos, which gives me a good sense of whether the food might be good.
I agree Yelp has become less relevant and needs to create more personalized suggestions. I think a quick follow up asking if you liked the food is a great idea. You could even follow Uber’s approach of forcing you to review something before using the app again. I suggest this because Open Table always sends me an email asking about the food and I never bother to rate it but if I needed to rate it quickly before searching yelp again, I rate the food. I have come to rely on Yelp’s photos more and more. I wonder if there is a visual way to display photos before or after you click on a restaurant so you can get a feel for the ambiance and food faster than reading through reviews on it.
I think this is very interesting insight into the world of online reviews. Personally I take every review on Yelp, and similar sites, with a grain of salt. I’ve always felt that the ratings come from either the extremely satisfied or the extremely upset and often fail to show the real quality of a restaurant. In a lot of ways the site has made the average person believe they’re a qualified food critic, which isn’t always useful. Like you suggested, if they could somehow create filters so that users could only view reviews from trusted sources or people who have similar tastes it would be a lot more useful.
Very good post. Really insightful analysis from the data you collected. I wonder if asking users to rank a subset of options is the alternative though. It is known that recent memories are more vivid that older ones, which could certainly introduce a bias towards the rank the place you just visited “higher” than the ones it’s compared against. I wonder if adding some type of disincentive to over-rate a restaurant would work in addition to forcing all customers to rate their experience before using the app again. For example, enforcing to rate individual criteria when giving a 4 or higher might disincentive customers to just give 4’s to most restaurants.
As a power Yelp user, I have noticed that the quality of the rating from the masses have begun falling short in the last couple of years. Your data analysis demonstrates exactly what’s been happening. That being said, I do believe there is additional value in showing the aggregate average rating and quantity of reviewers for the restaurant as it somewhat negates the attempts of many social media-savvy restaurants to plant good reviews to jumpstart their Yelp presence. Your recommendations for their next product iteration is on point. Personalized recommendations would make the dataset much more powerful and relevant, but certainly the large database is a critical moat from competitors like Swarm, whose recommendations just haven’t been as accurate or reliable as Yelp.
Great post, thank you for the data analytics, I think we have all started to become ever more skeptical with Yelp reviews.
Aside from the clustering effect of ratings, another problem with Yelp reviews is the circularity of it all, a good restaurant gets good reviews people go to the restaurant, have a good time, great review etc. As more people rely on Yelp reviews to find restaurants, it makes it hard for newer, harder to find restaurants to get in the picture. This happened to me in New York a lot, generally a greatly reviewed place would be packed with people and because of this review-frenzy one would feel uneasy going to an under-reviewed (and potentially vacant) new place. I wonder if Yelp could do something to mitigate this so as to help foodies like me discover new and exciting places.
Very interesting analysis! I like your observation that Yelp has so much data that they could be deriving a lot more value out of. Going along your idea of personalized recommendations, what if the data from Yelp can power the voice assistants Siri, Cortana, or Google Now? It’s always a mystery to me how the voice assistants can answer the question: “what’s a good restaurant around here?” If Yelp can harness the power in their data, they can make a really powerful assistant.