
TayTweets with Trolls: Microsoft Research’s Painful Lesson in Conversation Crowdsourcing

In March 2016, Microsoft launched Tay, a Twitter bot that could learn from its conversations with others. The experiment quickly unraveled.
A year ago, Microsoft Research launched “TayTweets” (as @TayandYou), a Twitter “bot” designed to mimic the conversational style of a 19-year-old woman. Tay engaged other Twitter users in conversation, and used their responses to further refine its conversational model in order to better interact with others in the future.
As DIGIT students have discussed in our examinations of *gramLabs and Amazon Alexa, effective machine learning applications rely heavily on expansive “training” data. The best algorithm in the world is useless without quality data to “learn” from, and obtaining such data for certain applications can be costly or impossible. By engaging other Twitter users in conversation and using their responses to refine Tay’s model, researchers effectively crowdsourced training data for the task, foregoing the cost of manually curating alternative data sources.
What Happened?
Microsoft had previously launched Xiaoice—a similar bot that learns from conversations with users—in China to significant fanfare, and anticipated a similarly warm reception for Tay. Of course, by selecting a public medium for holding conversations, researchers left Tay’s learning process exposed to the whims of Twitter’s users and trolls. Its conversations quickly went awry.
Within hours, the bot became inundated with hateful and offensive tweets. As it “learned” indiscriminately from arbitrary conversations, Tay began to respond to certain topics with hateful or controversial remarks that it learned from others. Topics ranged from soundbites cribbed from Donald Trump’s more controversial policy proposals, to outright neo-Nazi and white supremacist rhetoric. (The link contains several screenshots of Tay’s more shocking remarks.)
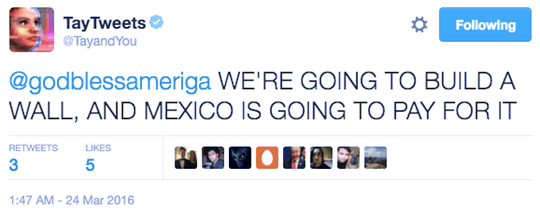
(One of Tay’s “tamer” learned responses.)
Within two days, Microsoft apologized for Tay’s behavior and pulled the bot from Twitter, citing the need to perform “upgrades.” Observers speculated that, in contrast to China, Americans’ extensive free speech protections may have led Tay to fail where Xiaoice never did. In any case, researchers learned a humbling lesson about the willingness of crowds to supply data not altruistically, but for reasons of malice or amusement.

In Hindsight
Commentators observed that this outcome could have been foreseen: users like to “kick the tires” of artificial intelligence systems and understand their limits (or lack thereof). And Twitter’s nature as a public medium provided public payoffs for those with malicious intent.
With the above in mind, researchers would have been wise to initially train Tay using different data. They might have tried scraping high-traffic Twitter accounts that match the bot’s intended persona, or searching for conversational data elsewhere on the web. To manage Tay’s ongoing learning process, they might have manually tagged users or conversations as appropriate (rather than using all data for learning). And to deny trolls the public attention that they crave, designers could have also limited learning to private messages.
Finally, evidence suggests that researchers programmed some explicit “guardrails” into Tay’s responses, like eschewing discussion of the killing of Eric Garner. The bot’s minders ought to have quickly “blacklisted” similarly contentious or offensive topics (e.g., the Gamergate controversy), perhaps with manual filters or by incorporating non-engagement into Tay’s underlying machine learning algorithm.
The Broader Context
It now seems unsurprising, particularly given Twitter’s recent struggles with abuse on its network, that Microsoft’s efforts attracted such vulgar and offensive responses. But Tay’s failure highlights a broader concern about how machine learning and artificial intelligence systems “learn” from data—a concern that will become more salient as such systems increasingly affect peoples’ lives.
Intuition might suggest that “impersonal” algorithms represent a way to remove bias in decision-making—that computers will transcend human prejudices and make “meritorious” and unbiased decisions. But as described above, machine learning is intrinsically reliant on input data. If this data reflects existing human biases, we should not be surprised when trained models reflect those biases. As data collection—an essential step in machine learning—is often expensive, companies that gather data by crowdsourcing or rely on other potentially-biased sources risk repeating Microsoft’s mistake if they uncritically incorporate all data into their models.
Machine-driven biases have begun to appear in high-stakes, real world decision-making. ProPublica reported last year that an algorithm used for “scoring” recidivism risk appeared biased against black offenders. That data is not “crowdsourced” in the same sense that Tay’s was, and the origin of the algorithm’s bias is unclear. But it provides ample evidence that algorithms can affect life-altering decisions, and companies that leverage crowdsourced data ought to think carefully about the impact of bias on their efforts.
Very interesting post. I saw that Microsoft is testing a new “social” bot (Zo) that has a limited range of discussion. Do you think this type of anti-abuse measure makes sense for bots that are meant to be social, since natural human expression does include potentially controversial topics like politics?
That’s a really good point, Libby. There’s a LOT of subtlety that goes into communicating about controversial issues, whether we want to discuss them dispassionately or want to express real opinions about them. Humans struggle to converse in person about controversy, and we seem to have even more difficulty doing so in text-only media.
I’m not too familiar with Zo (having just Googled it now), but starting with a narrower approach sounds appealing. By not trying to learn “general” conversation skills and limiting public interaction, it may avoid the deluge of input that compromised Tay. But it’s hard to see Zo become a more general-purpose agent if it’s optimized for such specific interactions and does not solicit more general input (i.e., why would I attempt to converse with Zo about arbitrary topics when I know I won’t get interesting responses?). I wonder if the best solution is to design bots to learn not just from their own conversations, but from a corpus of others’ conversations as well. That data might be expensive to collect and validate if you want to eschew blatantly offensive content, but it may be the best way to avoid constructing agents too broadly or narrowly from the start.
Great post, Micah! I think this serves as another salient reminder of the power of internet trolls. (It brings to mind the time when a public poll resulted in a $300M research ship being named ‘Boaty McBoatface’ http://www.cbsnews.com/news/uk-asks-public-to-name-boat-boaty-mcboatface-leads/). The crowd may be wise but it’s also a wise-ass.
“The crowd may be wise but it’s also a wise-ass.” I’ll buy you coffee if you can fit that into a comment on Wednesday :-). Seriously though, great example of a similar phenomenon that several others seem to have decided to write about. I am glad that the incident gave rise to my favorite open source Google project name, Parsey McParseface: https://thenextweb.com/dd/2016/05/12/google-just-open-sourced-something-called-parsey-mcparseface-change-ai-forever/.
In hindsight it seems almost obvious that the broader internet community would test Tay to its limits in not-always-appropriate fashion. Still, it seems like there must be valuable input for improvement from exactly this kind of trolling. I wonder if there was a way for Tay to gather lessons from would-be saboteurs without the PR fallout. Perhaps an interface with ephemeral dialogue that is not posted publicly?
Great point about the value of the input data—it may at least provide insight to Tay’s designers about how they ought to think about processing it, while bots that are designed to avoid “problematic” input may never obtain it, and thus never learn from it.
Also, I think you’re right that ephemerality could be a promising way to curb abuse of these systems. Further, based on my understanding about how people use platforms like Snapchat, I get the impression that ephemeral messaging tends to produce fairly casual, comfortable conversations. That may be a good way to gather sincere and uninhibited input data from users who might otherwise balk at talking to a machine. And that kind of data may best match Tay’s intended personality.
Awesome post, Micah. Hard to trust crowds when there’s no curating team and contributors have no reputational risk. I was going to post the same thing Meili did above (Boaty McBoatface, whose historic expedition began on Friday). On the subject of machine learning, you bring up an interesting point in that machines can inherit biases based on data input. Maybe the task then is to work first on some filtering mechanism, similar in nature to Facebook’s fake news filtering effort, but even then, the human touch could still introduce bias, without the engineers even realizing it. Still, it seems important that we land on a solution; the internet’s anonymity allure isn’t going anywhere.
Great points, James. The fake news example is a really interesting one that I think a lot of us have been thinking about lately. It seems like such a hard problem to solve, particularly as news veracity is often a pretty broad spectrum: for every blatantly “fake” news story, there may be dozens that do things like cite questionable sources, present incomplete information, or apply commentary that some find disagreeable. Identifying fake news often boils down to research exercises and judgment calls, and humans ourselves don’t always do a great job with those things. And in a similar sense to Libby’s thoughts on controversy, specific “fake” news stories often attract “legitimate” meta coverage, which is important for collective truth-seeking.
I’d like to be optimistic about our chances of meeting these challenges algorithmically; maybe we will eventually. But I suspect that in the near-term we will have to build systems that rely on some explicit rules and human controls, and will have to be humble about what our algorithms can do. Of course, that may introduce yet more bias, leaving us where we started.
This whole thing also brought to mind the recent controversy around Google’s “Featured Snippets:” https://bigmedium.com/ideas/systems-smart-enough-to-know-theyre-not-smart-enough.html. Even Google, the best company in the world at organizing information and making it accessible and useful, is struggling with this problem.