
Google X: Leveraging data and algorithms for self-driving cars

Is Google X going to win in the self-driving car space? Are Waze and Google Maps their secret weapons? How does Google X's Waymo project leverage the power of data and analytics?
TBD
Meet Waymo
Waymo is Alphabet’s self-driving car project that was spun-off as a separate company just last December. It announced last May a partnership with Fiat Chrysler to modify 100 Chrysler Pacifica Hybrid minivans with Google’s proprietary autonomous technology and test them on public roads around Mountain View, allowing the company to gather copious amounts on data on safety and system performance [1]. According to Google, the self-driving cars have driven more than 2 million miles [2].

Exhibit 1: Waymo’s own car design. 2016.

Why is big data a big deal in self-driving cars?
To gather data on the real-time surroundings, each car is equipped with numerous sensors. According to an estimate, a Google car produces around 1GB of sensor data per second (!) [3]. That would add up to 2 Petabytes of data per year (2 million GB) per car, assuming that the average American drives 600 hours a year. Of course not all this data is important and will have to be stored. Currently the servers needed to process this data are in the car’s trunk and require their own large cooling system. The data produced by the car can be classified in three ways:
- Technical data (inside-out): how the car learns about avoiding obstacles such as cones or cyclists; it’s the data that comes from the car’s sensors and is analyzed by the car’s machine learning algorithms,
- Community data (outside-in): crowd-sourced data about traffic and driving conditions from Waze-like platforms
- Personal data: riders’ personal preferences regarding driving locations, indoor temperature, in-car entertainment etc., all serving to improve the user experience.
Google’s autonomous cars collect all three kinds of data, but most of the processing power is used in consolidating technical and community data — most of the data is coming in real-time and the cars needs to make split-second decisions based on it.
Data + Learning
The crux of the issue is for Waymo to not only collect data about the car’s surroundings, but to implement learning algorithms and improve the driving ability, the more data the company gathers and analyzes. For example, a car can start to tell the difference between a water bottle and a rolled newspaper and incorporate that learning in future situations. It can tell when a pedestrian is ready to cross the street by observing behavior over and over again. Algorithms can sort through what is important, so that the car will not need to push the brakes every time a small bird crosses its path. Hence, the car uses both predictive as well as prescriptive models to improve its ability to recognize and react to its surroundings. With every next mile driven, the cars become safer and more reliable – showing clear and strong network effects.
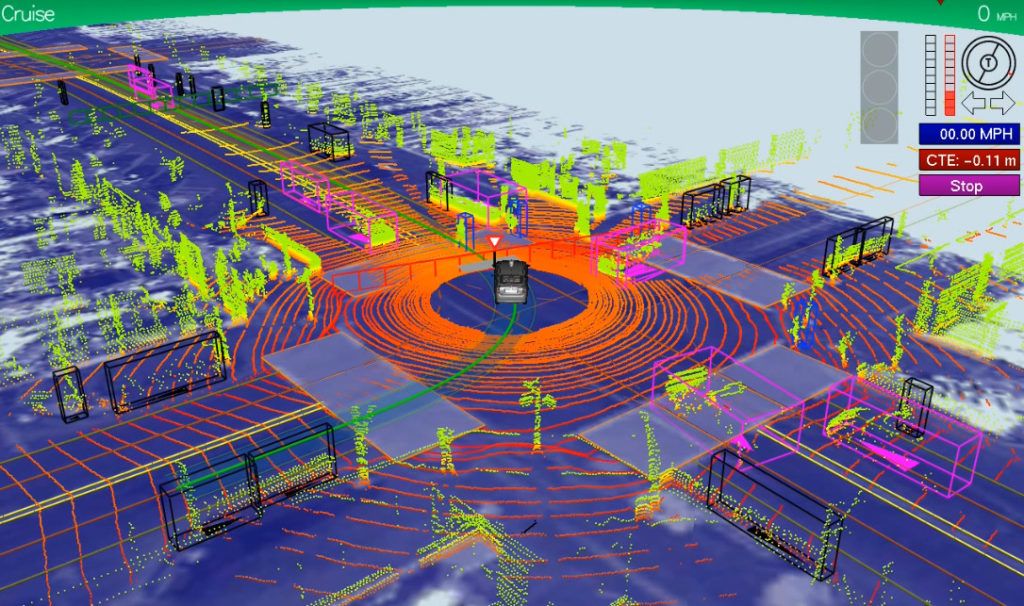
Exhibit 2: How the Google Car sees the road. 2016.
Competitors keep Waymo on its toes
Even today, there are many stumbling blocks on the path to developing the most reliable self-driving car technology. Lawsuits and allegations for data theft have become the rule rather than the exception. For example, Waymo and Alphabet recently filed a suit against Uber and its recent acquisition Otto ($680M deal) for data theft by former employees regarding R&D and performance data of Waymo’s LiDAR system [4]. Many other large automotive companies such as Tesla, Hyundai, Mercedes, Ford, GM, and Honda have all started their own self-driving car projects. Each of these competitors is also on the quest for collecting data. As Intel’s CEO Brian Krzanich has pointed out, “Data is the new oil”[5].
The Future holds both Challenges and Opportunities
Along with safety concerns, Google’s self-driving car will create never-before seen security and personal data issues. One serious issue might be hackers who could take control over the car. Moreover, cars will expose personal location data, giving way for intruders or even advertisers to take advantage of this sensitive information.
 One of the opportunities that big data creates for autonomous cars in the future is to create a larger connected network of cars, which will be able to communicate with each other. They could also interact with roadside wireless sensor networks to sync up information about traffic lights or accidents. By making the technology more and more reliable, self-driving cars have the potential to eventually become safer than human drivers and replace those in the not so distant future.
One of the opportunities that big data creates for autonomous cars in the future is to create a larger connected network of cars, which will be able to communicate with each other. They could also interact with roadside wireless sensor networks to sync up information about traffic lights or accidents. By making the technology more and more reliable, self-driving cars have the potential to eventually become safer than human drivers and replace those in the not so distant future.
Going back to the motto that “data is the new oil” – data is transforming the way we think about transportation. Data has the potential to make driving more accessible and safe, by opening up new opportunities and creating new insights. As data becomes the new paradigm in transportation, the winners will be those who are able to harness the power of this data and create responsive, learning, and connected vehicles that move people and cargo around.
Sources:
[1] http://fortune.com/2017/03/27/waymo-self-driving-minivans-snow/
[2] http://www.reuters.com/article/us-google-autonomous-idUSKBN142223
[3] https://datafloq.com/read/how-autonomous-cars-will-make-big-data-even-bigger/1795
[5] https://newsroom.intel.com/editorials/krzanich-the-future-of-automated-driving/
Thanks for a great post. One thing this made me consider is what is Google’s goal in terms of Value Capture? If data is going to be the most important tool in the self-driving car system I can imagine that Google might want to own that data and sell it, rather than be the one actually producing/selling self-driving cars. Gathering this data first and creating an effective software platform for the running of driverless cars could allow Google to capture a lot of the future value of this new industry.