
Gmail: ensuring a spam-free inbox with Machine Learning

Gmail tirelessly improves its spam filters to identify exactly which messages shouldn’t make it to your inbox
Around 90% of emails sent around the world are spam [1]. Luckily, Google has spent significant time and money on Gmail’s spam filters, making them very effective at making sure the vast majority of these spam emails don’t make it to our inboxes.
How do they do it? By constantly refining their spam filter algorithms.
Gmail looks at various inputs for each email (see Exhibit): who is the sender (and what we already know about them), what’s their IP address, what is the content etc., and tries to classify it as either “spam” or “not spam”. If an email is deemed “not spam”, it shows up user’s inbox – otherwise it’s sent directly to the “spam” folder. But then, importantly, Gmail also monitors users’ behaviors to refine its filter’s decision-making process. By monitoring users’ engagement with the email, it can close the feedback loop and improve its predictive power. If, for example, emails with the words “Magic pill” and “weight loss” tend to be flagged by users as “spam”, or are just deleted as soon as they are received, the Gmail team might decide to penalize emails with those words, increasing the likelihood of blocking them. In fact, in all likelihood, the Gmail team doesn’t discuss such individual decisions, but rather on rules to apply so that the algorithm picks up on these patterns on its own. Ever pushing to improve its filter, this year Gmail announced that it will expand the list of things its filter looks at to include each recipient’s taste, as inferred for their Gmail activity history (e.g., what they’re generally interested in) [2]. Oh, and if this smells like direct network effects to you, you’re not mistaken.

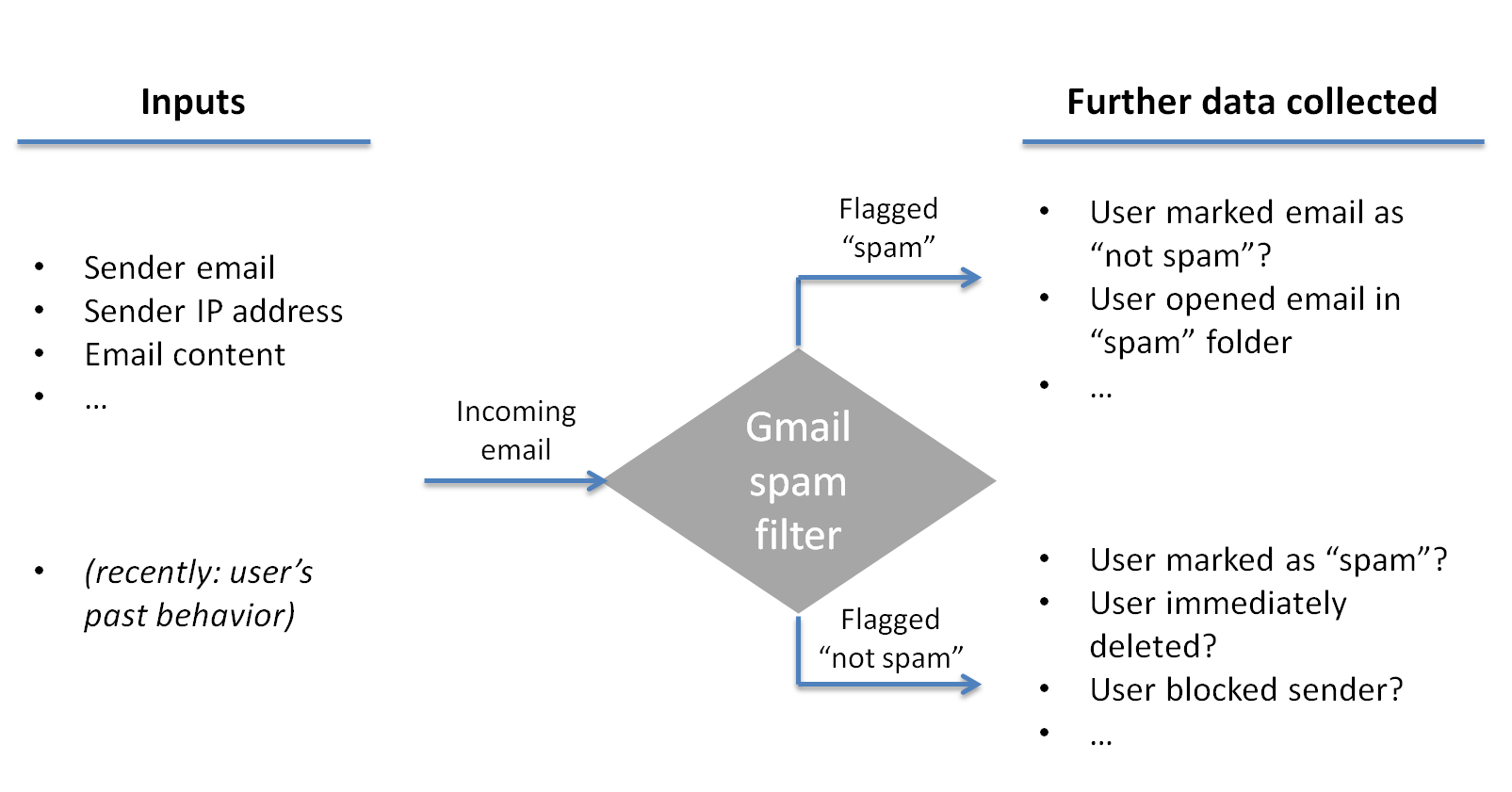
The value created to users is significant. With almost a billion users [3], and using my own personal spam folder to estimate 20 spam emails per day, and ~1 second saved per spam email, I estimate ~200,000 man-years saved per year. On a per-user basis the numbers are not as impressive, but with little differentiation between email services, a bad spam filter just might be what’s needed to make a user switch. That is not to mention the benefit of not falling prey to the various scams out there.
The value is captured somewhat indirectly. By offering a better email experience, Google hopes to get even more users to switch to Gmail, and to use it more extensively (at the expense of its competitors). With more users, Gmail can of course display more email ads. But even more than that, there are multiple synergies with Google’s other products, the most obvious one is probably better targeting of Google search ads based on the user’s online behavior, as it’s manifested in their email account (e.g., if a user receives lots of emails from Amazon, maybe they’re more likely to click a link to Amazon’s website).
This brings us to two unique challenges faced by Gmail, when designing its spam filters. One, it never actually observes whether it made the right decision. It can use proxies, such as whether the user ignored the message, or deleted it, as a proxy to whether they were interested in receiving it in the first place. But it doesn’t really know – maybe the user wanted to receive the email, but was just quick to process the information contained in it. Another challenge is understanding the cost/value of a false negative and false positive. Unlike a gaming company that can easily track whether they increased spending per user, with spam filters, it’s not obvious whether the users are actually better off after making a change, and even more so whether Google overall is better off with all the aforementioned synergies.
Going forward, the spam filter development is likely to continue its cat-and-mouse dynamic. Spammers are constantly trying to adapt to the rules adopted by Gmail’s spam filters. Already the internet is full of lists such as “16 Ways To Get Your Email Past Spam Filters” [4]. What’s almost certain though, is that the world today is far more spam-free than it was ten years ago (e.g., 2010 showed an ~80% drop is spam volume [5]) – perhaps a result of better filtering eroding the financial upside of spamming – making the digital world a better place.
References
Photo credit: techydudes.com
[1] – https://www.m3aawg.org/sites/default/files/document/M3AAWG_2012-2014Q2_Spam_Metrics_Report16.pdf
[3] – https://plus.google.com/+Gmail/posts/AjktcDswdKh
[4] – https://expresspigeon.com/blog/2014/07/28/avoid-spam-filters
[5] – http://www.symantec.com/connect/blogs/why-my-email-went
Great post! No doubt in my mind that this is hugely value creating. Google is trying out other products leveraging the very same technology of machine learning: Google Inbox for example does exactly the same thing with regular e-mail as it does with spam, recognizing that many automatically generated messages are actually not spam (tickets, boarding passes, purchase confirmations, newsletters etc) and could use some categorization. The more you use Google Inbox, the more accurately it assigns the categories, helping you organize your e-mail content. Your 1-second argument holds!
Very interesting post! What is striking about many machine learning models is that the primary data that the machine seeks to “learn” from is users’ actions. Recommendation engines also find such algorithms really useful. There are primarily two different ways to think about recommendation engine algorithms: find similar items, and find similar users. The first approach seeks to assign certain properties/attributes to each item (e.g., videos in the case of Youtube, or products in the case of Amazon), and then recommends new items which have properties similar to the item being viewed/purchased. The second approach assigns properties/attributes to users to segment them into clusters, then recommends what other users in the same segment viewed/purchased. Most recommendation engines find the latter approach to be more effective and have greater “predictive” power than the former.
Cool post and I especially like the bit about the challenges, particularly the impact of false positives and false negatives. I think false negatives (and the low incidence in Gmail), as you indicated initially, are what elevate Gmail’s product above others. Enough false negatives, i.e. spam emails that end up in your inbox, could eventually drive a user away. What worries me much more are false positives – how often do users actually go into their spam folder and check to see if there are any relevant emails? Based on my own anecdotal evidence, that action is very rare. However, one case of an important email inadvertently making it into the spam folder is likely to be far more damaging to the Gmail product than many false negatives. As a result, Gmail should be very cautious with their algorithm and give a very high priority to data around “spam” emails that a user marks as “not spam”.